Invirtiendo una serie de tiempo diferenciada por fracciones


Python | Pandas | Numpy | Matplotlib | Series de Tiempo
López de Prado en su libro “Advances in Financial Machine Learning (Wiley, 2018)” explica una metodología para diferenciar series de tiempo por fracciones. El argumento para justificar ésta transformación, es que los métodos tradicionales como la diferenciación entera remueven la memoria que tienen los precios. En el texto, él desarrolla un procedimiento para calcular de forma eficiente la diferenciación por fracciones a una serie de tiempo financiera, conservando su memoria y garantizando su estacionariedad. Allí, él desarrolla una serie de códigos que permiten realizar el proceso de diferenciación de las series, pero no implementa un código para reconstruir o invertir una serie de tiempo a su escala original, algo que en el momento de escribir el artículo no he encontrado en ningún lado, razón por la cual decidí desarrollar un código que permita “reescalar” una serie diferenciada por fracciones.
En el libro se define una serie de tiempo diferenciada por fracciones como:
Donde:
: Es el valor diferenciado por fracciones en t
: corresponde a un vector de lecturas de precios
: Es un vector de pesos hallados iterativamente en el tiempo
Como las series de tiempos en la práctica no son infinitas, el autor propone un método para establecer una ventana de longitud fija que garantice la estabilidad en los valores diferenciados y sea menos costoso computacionalmente. La forma de hallar la dimensión de la ventana es mediante un proceso iterativo de estimación de pesos que están en función de una fracción , su posición en el tiempo de la serie y un umbral .
Cuando se alcanza el máximo de pesos a utilizar en la diferenciación, y por lo tanto, se establece la dimensión de la ventana del vector .
El factor deberá cumplir las siguientes condiciones:
Entonces, la serie de tiempo diferenciada se puede reescribir de ésta manera:
Luego, sí se conoce el vector de pesos para una ventana de longitud y el vector de precios en el rango , es posible a partir del producto de estos dos vectores, conocer el valor inverso en el tiempo .
El código de python para hallar es:
def reconstructed_values(Differenced, w_l, original, start):
'''
Differentiated: Forecasted time series differentiated by fractions to be reconstructed.
w_l: Constant weight vector (fixed window = l)
original: Data vector of the original time series of
dimension equal to w_l - 1
start: Index where data inversion begins in df.
It is the last index of the df of the
undifferenced time series.
'''
original = np.array(original).flatten()
Differenced = np.array(Differenced).flatten()
n = len(Differenced)
y_hat_reconstructed = []
for f in range(n):
y_hat = (Differenced[f] - np.dot(w_l[:-1].T, original))[0]
y_hat_reconstructed.append(y_hat)
original = np.append(original[1:], y_hat)
return y_hat_reconstructed
Lo que hace éste código es tomar el valor pronosticado de una serie de tiempo diferenciada y, restarle la suma producto de dos vectores: con los pesos del fraccionamiento y los precios , ambos comenzando en . Obteniendo como resultado, un valor proyectado en la escala original de la serie de tiempo.
Experimento numérico
Para probar el código se descargaron del sitio web de NASDAQ, los precios históricos de la acción NVIDIA con un rango de fechas entre el 26 de marzo de 2015 y el 25 de marzo de 2025. Estos se cargan en un dataframe de pandas para facilitar su manipulación. La serie a diferenciar por fracciones es la de los precios de cierre ('close').
| date | close | volume | open | high | low |
|---|---|---|---|---|---|
| 2025-03-25 | 120.69 | 167,447,200 | 120.545 | 121.290 | 118.92 |
| 2025-03-24 | 121.41 | 228,452,500 | 119.880 | 122.220 | 119.34 |
| 2025-03-21 | 117.70 | 266,498,500 | 116.940 | 117.990 | 115.42 |
| 2025-03-20 | 118.53 | 248,829,700 | 116.550 | 120.200 | 116.47 |
| 2025-03-19 | 117.52 | 273,426,200 | 117.270 | 120.445 | 115.68 |
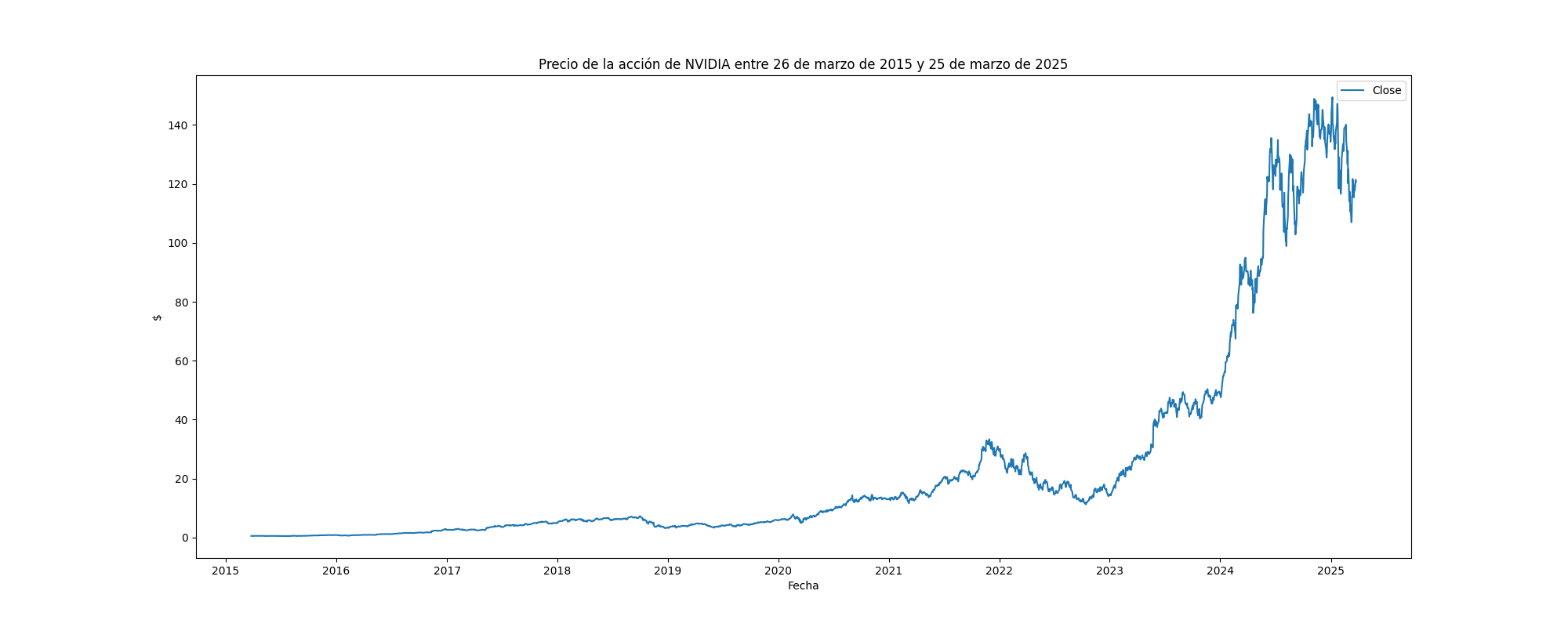
Antes de la diferenciación se hace la prueba ADF para validar si ésta es estacionaria o no. El resultado, como era de esperase con cualquier serie de precios financiera, resultó que la serie no es estacionaria:
Results of Dickey-Fuller Test for column: close
Metric Value
0 Test Statistic 0.967872
1 p-value 0.993915
2 No Lags Used 1.000000
3 Number of Observations Used 2513.000000
0 Critical Value (1%) -3.432955
1 Critical Value (5%) -2.862691
2 Critical Value (10%) -2.567383
Conclusion:====>
Fail to reject the null hypothesis
Data is non-stationary
Análsis de pesos
Para entender un poco como funcionan los umbrales y su relación con los órdenes de diferenciación por fracciones , corrí tres experimentos con la función de pesos:
Experimento 1 - Pesos para un orden de diferenciación variable y umbral constante
t = 1e-5
for d in np.arange (0, 1.1, 0.1):
vec = getWeights_FFD(d, t)
n = vec.shape[0]
print(f"Fractional Order d: {d:.2f}, threshold: {t}, Vector dimension: {n:,}")
| d | Umbral | W dim |
|---|---|---|
| 0.00 | 1e-05 | 1 |
| 0.10 | 1e-05 | 4,076 |
| 0.20 | 1e-05 | 3,382 |
| 0.30 | 1e-05 | 2,275 |
| 0.40 | 1e-05 | 1,458 |
| 0.50 | 1e-05 | 927 |
| 0.60 | 1e-05 | 590 |
| 0.70 | 1e-05 | 372 |
| 0.80 | 1e-05 | 228 |
| 0.90 | 1e-05 | 125 |
| 1.00 | 1e-05 | 2 |
De ésta tabla se puede inferir que a menor , mayor cantidad de datos históricos requeridos.
Experimento 2 - Pesos para un orden de diferenciación constante y umbral variable
d = 0.1
for i in range(1, 6):
t = 10 ** -i
vec = getWeights_FFD(d, t)
n = vec.shape[0]
print(f"Fractional Order d: {d:.2f}, threshold: {t: .5f}, Vector dimension: {n:,}")
| d | Umbral | W dim |
|---|---|---|
| 0.10 | 0.10000 | 1 |
| 0.10 | 0.01000 | 8 |
| 0.10 | 0.00100 | 62 |
| 0.10 | 0.00010 | 503 |
| 0.10 | 0.00001 | 4,076 |
De la tabla se observa que a menor valor en el umbral , es necesario tener una dimensión mayor para los vectores utilizados, pues un menor umbral implica que la longitud que define el tamaño de la ventana sea más grande.
Experimento 3 - Pesos para un orden de diferenciación variable y umbral variable
| d | Umbral | W dim |
|---|---|---|
| 0.1 | 0.10000 | 1 |
| 0.1 | 0.01000 | 8 |
| 0.1 | 0.00100 | 62 |
| 0.1 | 0.00010 | 503 |
| 0.1 | 0.00001 | 4,076 |
| 0.2 | 0.10000 | 2 |
| 0.2 | 0.01000 | 11 |
| 0.2 | 0.00100 | 73 |
| 0.2 | 0.00010 | 497 |
| 0.2 | 0.00001 | 3,382 |
| 0.3 | 0.10000 | 3 |
| 0.3 | 0.01000 | 12 |
| 0.3 | 0.00100 | 66 |
| 0.3 | 0.00010 | 388 |
| 0.3 | 0.00001 | 2,275 |
| 0.4 | 0.10000 | 3 |
| 0.4 | 0.01000 | 11 |
| 0.4 | 0.00100 | 55 |
| 0.4 | 0.00010 | 282 |
| 0.4 | 0.00001 | 1,458 |
| 0.5 | 0.10000 | 3 |
| 0.5 | 0.01000 | 10 |
| 0.5 | 0.00100 | 44 |
| 0.5 | 0.00010 | 200 |
| 0.5 | 0.00001 | 927 |
| 0.6 | 0.10000 | 3 |
| 0.6 | 0.01000 | 9 |
| 0.6 | 0.00100 | 34 |
| 0.6 | 0.00010 | 140 |
| 0.6 | 0.00001 | 590 |
| 0.7 | 0.10000 | 3 |
| 0.7 | 0.01000 | 7 |
| 0.7 | 0.00100 | 26 |
| 0.7 | 0.00010 | 97 |
| 0.7 | 0.00001 | 372 |
| 0.8 | 0.10000 | 2 |
| 0.8 | 0.01000 | 6 |
| 0.8 | 0.00100 | 18 |
| 0.8 | 0.00010 | 64 |
| 0.8 | 0.00001 | 228 |
| 0.9 | 0.10000 | 2 |
| 0.9 | 0.01000 | 4 |
| 0.9 | 0.00100 | 12 |
| 0.9 | 0.00010 | 38 |
| 0.9 | 0.00001 | 125 |
Como conclusión, un menor orden de diferenciación por fracciones y un menor valor de umbral , se traducen en ventanas mayores, lo que en un momento dado podría ser computacionalmente costoso.
Hallando el mínimo
Lopez de Prado facilita un código para encontrar el mínimo con un constante, pero no da reglas empíricas o recomendaciones para encontrar el umbral. El código podría fácilmente adaptarse también para encontrar un mínimo para un dado, que mantenga la correlación entre precios diferenciados alta.
Para la acción de Nvidia se toma el valor que define el autor en su código por defecto de . En el siguiente gráfico y tabla se muestran los resultados al correr el código para esta serie.
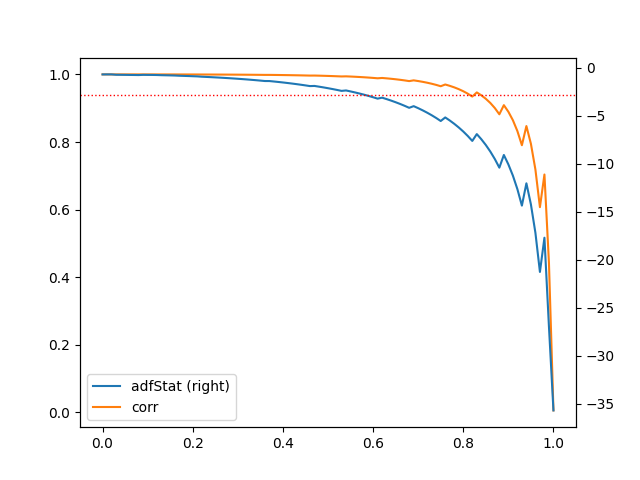
| d | adfStat | pVal | lags | nObs | 95% conf | corr |
|---|---|---|---|---|---|---|
| 0.59 | -2.9309190 | 4.186890e-02 | 1.0 | 2507.0 | -2.862694 | 0.990603 |
| 0.60 | -3.0671440 | 2.908214e-02 | 1.0 | 2507.0 | -2.862694 | 0.989608 |
| 0.61 | -3.2121900 | 1.928982e-02 | 1.0 | 2507.0 | -2.862694 | 0.988498 |
| 0.62 | -3.1130540 | 2.560210e-02 | 1.0 | 2508.0 | -2.862693 | 0.989446 |
| 0.63 | -3.2608490 | 1.672185e-02 | 1.0 | 2508.0 | -2.862693 | 0.988310 |
| 0.64 | -3.4186370 | 1.033970e-02 | 1.0 | 2508.0 | -2.862693 | 0.987038 |
| 0.65 | -3.5872890 | 6.008746e-03 | 1.0 | 2508.0 | -2.862693 | 0.985612 |
| 0.66 | -3.7677690 | 3.254836e-03 | 1.0 | 2508.0 | -2.862693 | 0.984010 |
| 0.67 | -3.9611580 | 1.628131e-03 | 1.0 | 2508.0 | -2.862693 | 0.982207 |
| 0.68 | -4.1686560 | 7.441879e-04 | 1.0 | 2508.0 | -2.862693 | 0.980175 |
| 0.69 | -3.9952210 | 1.435743e-03 | 1.0 | 2509.0 | -2.862693 | 0.982389 |
| 0.70 | -4.2058220 | 6.441076e-04 | 1.0 | 2509.0 | -2.862693 | 0.980340 |
| 0.71 | -4.4328000 | 2.595747e-04 | 1.0 | 2509.0 | -2.862693 | 0.978016 |
| 0.72 | -4.6778640 | 9.259045e-05 | 1.0 | 2509.0 | -2.862693 | 0.975373 |
| 0.73 | -4.9429520 | 2.874724e-05 | 1.0 | 2509.0 | -2.862693 | 0.972361 |
| 0.74 | -5.2302740 | 7.623369e-06 | 1.0 | 2509.0 | -2.862693 | 0.968919 |
| 0.75 | -5.5423530 | 1.690491e-06 | 1.0 | 2509.0 | -2.862693 | 0.964976 |
| 0.76 | -5.1699180 | 1.012439e-05 | 1.0 | 2510.0 | -2.862692 | 0.970126 |
| 0.77 | -5.4874100 | 2.213984e-06 | 1.0 | 2510.0 | -2.862692 | 0.966195 |
| 0.78 | -5.8350100 | 3.894946e-07 | 1.0 | 2510.0 | -2.862692 | 0.961642 |
| 0.79 | -6.2167010 | 5.344192e-08 | 1.0 | 2510.0 | -2.862692 | 0.956351 |
| 0.80 | -6.6371530 | 5.525763e-09 | 1.0 | 2510.0 | -2.862692 | 0.950178 |
| 0.81 | -7.1018690 | 4.148016e-10 | 1.0 | 2510.0 | -2.862692 | 0.942951 |
| 0.82 | -7.6173610 | 2.173901e-11 | 1.0 | 2510.0 | -2.862692 | 0.934455 |
| 0.83 | -6.9039880 | 1.260930e-09 | 1.0 | 2511.0 | -2.862692 | 0.946679 |
| 0.84 | -7.4383580 | 6.098123e-11 | 1.0 | 2511.0 | -2.862692 | 0.938129 |
| 0.85 | -8.0409090 | 1.848190e-12 | 1.0 | 2511.0 | -2.862692 | 0.927861 |
| 0.86 | -8.7241730 | 3.323050e-14 | 1.0 | 2511.0 | -2.862692 | 0.915458 |
| 0.87 | -9.5036680 | 3.392096e-16 | 1.0 | 2511.0 | -2.862692 | 0.900393 |
| 0.88 | -10.398710 | 1.934581e-18 | 1.0 | 2511.0 | -2.862692 | 0.881992 |
| 0.89 | -9.0790320 | 4.103830e-15 | 1.0 | 2511.0 | -2.862692 | 0.909020 |
| 0.90 | -10.057804 | 1.358413e-17 | 1.0 | 2511.0 | -2.862692 | 0.889523 |
| 0.91 | -11.224731 | 1.973438e-20 | 1.0 | 2511.0 | -2.862692 | 0.864576 |
| 0.92 | -12.632467 | 1.494475e-23 | 1.0 | 2511.0 | -2.862692 | 0.832370 |
| 0.93 | -14.351253 | 1.020839e-26 | 1.0 | 2511.0 | -2.862692 | 0.790504 |
| 0.94 | -12.028874 | 2.905450e-22 | 1.0 | 2511.0 | -2.862692 | 0.847192 |
| 0.95 | -14.222868 | 1.646269e-26 | 1.0 | 2511.0 | -2.862692 | 0.794765 |
| 0.96 | -17.187196 | 6.588184e-30 | 1.0 | 2511.0 | -2.862692 | 0.718440 |
| 0.97 | -21.256071 | 0.000000e+00 | 1.0 | 2511.0 | -2.862692 | 0.607307 |
| 0.98 | -17.693110 | 3.564761e-30 | 1.0 | 2512.0 | -2.862691 | 0.703871 |
| 0.99 | -26.948153 | 0.000000e+00 | 1.0 | 2512.0 | -2.862691 | 0.442550 |
| 1.00 | -35.672601 | 0.000000e+00 | 1.0 | 2512.0 | -2.862691 | 0.006055 |
Lo que hace el código es: para un constante, generar una serie de valores diferenciados por fracciones al iterar sobre en un rango . A cada conjunto diferenciado se le practica la prueba de ADF con y se les calcula su autocorrelación con un rezago de 1. El mínimo será aquel que primero cumpla la prueba de Dickey Fuller y que tenga la mayor autocorrelación. Como puede observarse de la tabla anterior, quien cumple estos criterios es un orden y una correlación de 0.9906, que es muy alta.
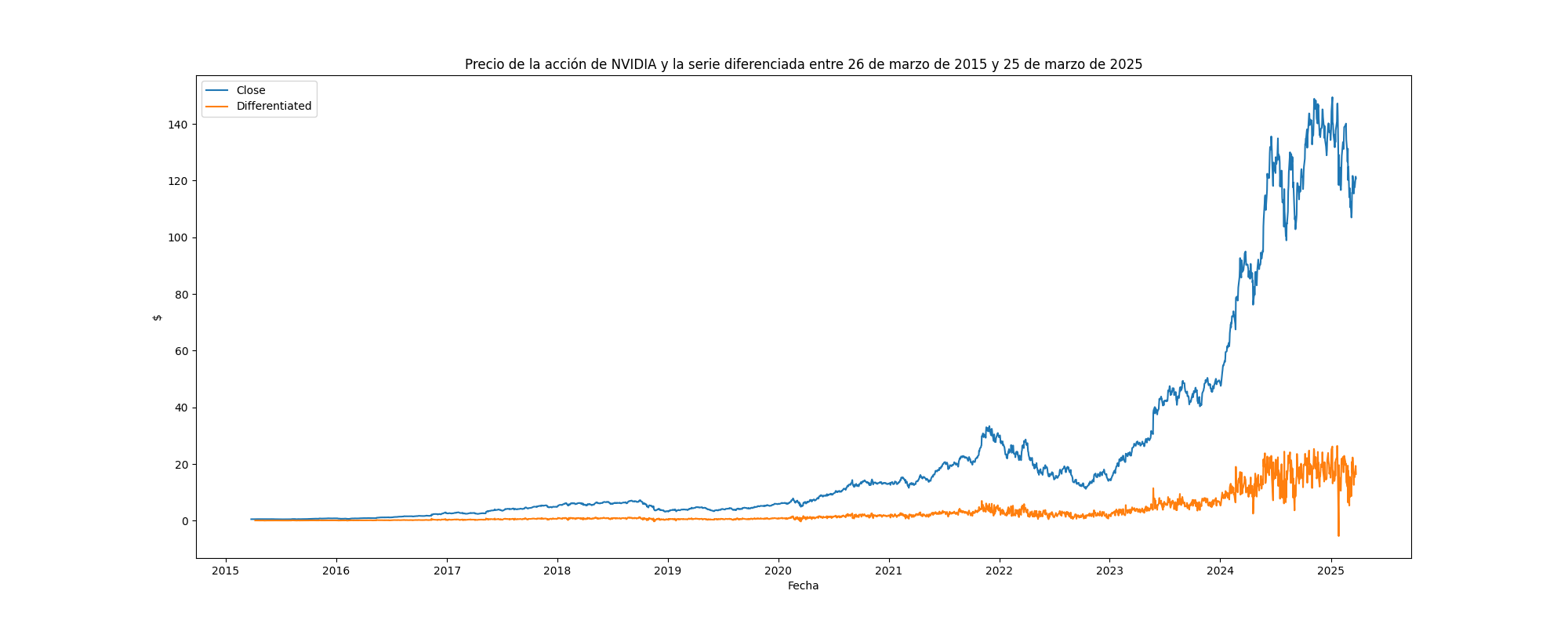
Diferenciando la serie
Se diferencia la serie de precios de cierre de Nvidia para un y . La serie resultante garantiza que sea estacionaria y preserva la memoria (correlación cercana a 1) de la serie original. En el siguiente gráfico se comparan ambas series (original y diferenciada).
Calibración del modelo ARIMA
Para esta parte del ejercicio se ajusta un modelo ARIMA a la serie diferenciada, empleando la librería auto_arima de python. Como la serie ya es estacionaria, se parametriza el orden de diferenciación en 0, convirtiéndolo en un modelo ARMA sobre una serie diferenciada por fracciones.
print(f'ARFIMA Model')
model = auto_arima(y_train,
start_p=1,
start_q=1,
max_p=15,
max_q=15,
d=0,
trace=True,
error_action='ignore',
suppress_warnings=True,
stepwise=True)
El modelo resultante es del orden ARMA(4,1), pero en la realidad es ARFIMA(4,0.59,1) por la diferenciación por fracciones de la serie de precios de cierre.
Pronóstico del modelo ajustado
Una vez ajustado el modelo se estima un pronóstico para una ventana de 5 días:
part = 5
forecast,conf_int = model.predict(n_periods= part,
exogenous = None,
return_conf_int=True)
El resultado se aprecia en la siguiente tabla:
| Date | |||
|---|---|---|---|
| 2025-03-19 | 11.64763945 | 16.895681 | 17.31862192 |
| 2025-03-20 | 11.57615336 | 17.002534 | 17.52886143 |
| 2025-03-21 | 12.01499720 | 15.379167 | 18.28738989 |
| 2025-03-24 | 12.03535028 | 19.351669 | 18.37617106 |
| 2025-03-25 | 12.12919879 | 16.467564 | 18.53661745 |
Estos datos corresponden al pronóstico de una media e intervalos de confianza del 95%, por lo tanto es necesario invertirlos para que los pronósticos tengan algún sentido económico o financiero.
Inversión de la serie diferenciada
Para invertir la serie diferenciada se empleará la siguiente función:
def forcast_ci_df(fdyh_lci,fdyh, fdyh_uci, w_l, original, start, end):
columns = ['y_h_lower', 'y_hat', 'y_h_upper']
reconstructed_l = reconstructed_values(fdyh_lci, w_l, original, start)
reconstructed_y = reconstructed_values(fdyh, w_l, original, start)
reconstructed_u = reconstructed_values(fdyh_uci, w_l, original, start)
reconstructed_array = np.array([reconstructed_l, reconstructed_y, reconstructed_u])
y_t = np.array(original.iloc[-1])[0]
y_hat_matrix = np.array([y_t,y_t,y_t])
y_hat_matrix = np.concatenate((y_hat_matrix.reshape(-1, 1), reconstructed_array),axis=1)
dates_index = pd.bdate_range(start=start, end=end)
return pd.DataFrame(y_hat_matrix.T, columns = columns, index=dates_index)
Los parámetros de entrada se explican a continuación:
- -fdyh_lci: Vector del intervalo de confianza inferior
- -fdyh: La serie diferenciada pronosticada
- -fdyh_uci: Vector del intervalo de confianza superior
- -w_l: Un vector de pesos para y definidos en la diferenciación de la serie
- -original: Un vector de precios desde el momento con las mismas dimensiones del vector de pesos menos uno
- -start: La última fecha de la serie de precios
- -end: La fecha en que termina la ventana del pronóstico en días laborales (de EUA en este caso)
En esta función se aplica la función
reconstructed_values(forecast, w_l, original, start)
a las series pronosticadas, y ésta devuelve un dataframe con las tres series invertidas a la escala original en $USD.
# fdyh_lc: Intervalo de confianza inferior resultante del pronóstico
# fdyh: pronóstico del modelo
# fdyh_uci: Intervalo de confianza superior resultante del pronóstico
part = 5
start = y_train.index[-1]
original = df[['close']][-len(w_l)-part+1:-part]
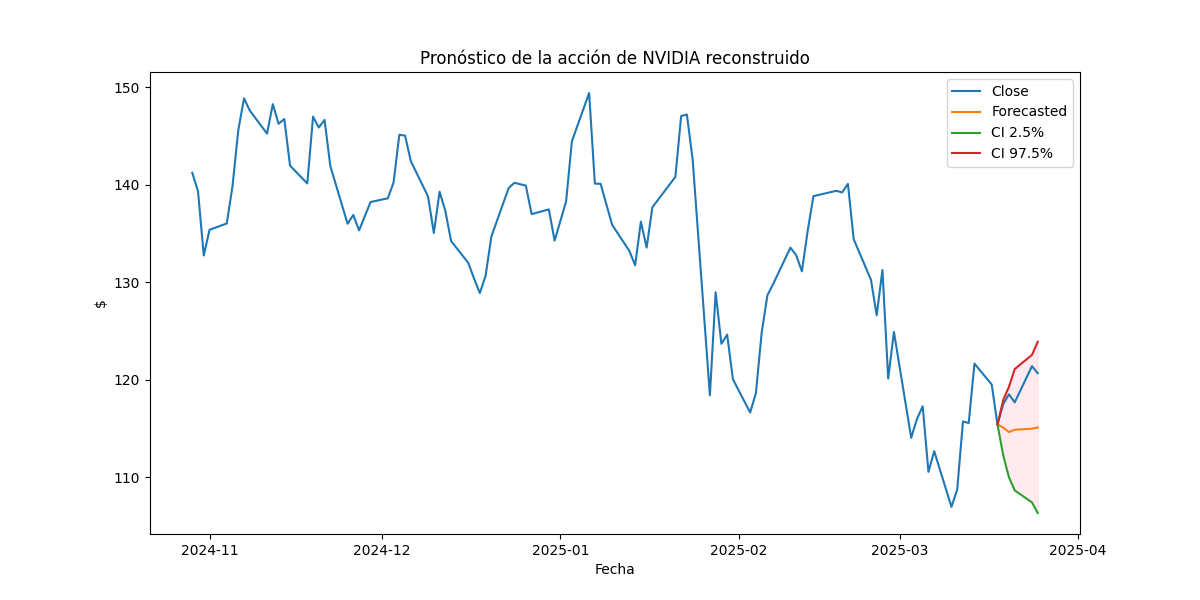
El resultado de esta transformación se presenta en la siguiente tabla:
| Date | |||
|---|---|---|---|
| 2025-03-18 | 115.430000 | 115.430000 | 115.430000 |
| 2025-03-19 | 112.271959 | 115.107450 | 117.942941 |
| 2025-03-20 | 110.007275 | 114.656569 | 119.305863 |
| 2025-03-21 | 108.672672 | 114.894904 | 121.117137 |
| 2025-03-24 | 107.438402 | 115.003449 | 122.568496 |
| 2025-03-25 | 106.352303 | 115.133381 | 123.914459 |
En el siguiente gráfico se muestra la serie invertida y sus intervalos de confianza, junto con la serie original.
Resumen
En éste artículo se muestra como una serie de tiempo diferenciada por fracciones puede ser invertida para llevarla a la escala original de precios $USD. Se presenta un ejemplo numérico con una serie de tiempo real. El código esté disponible en github
Tech stack: Python · Series de Tiempo · Statsmodels · Numpy · Panda · Matplotlib · Data Analysis
Notebook: github